

About repeated measure ANOVA in RTs analysis

Hi, everyone!
I have used repeated measure ANOVA in RTs analysis for a long time, and many published
papers also used it, but I don't know why.
For example (Simon effect), it is a 2 (target side: left vs. right) x 2 (response side: left vs. right) design. And there would be 4 conditions ( left-left, left-right, right-left, and right-right). In an experiment, each condition must be repeated several times, let's say 32 times. Is it this 32 is the repeated number in repeated measure ANOVA?
And I see the description of repeated measure ANOVA state that this measure takes place in different places and times, but the cognitive experiments seem not to fit that description.
In addition, when analysis, we will get a table is as follows (I made up the data)
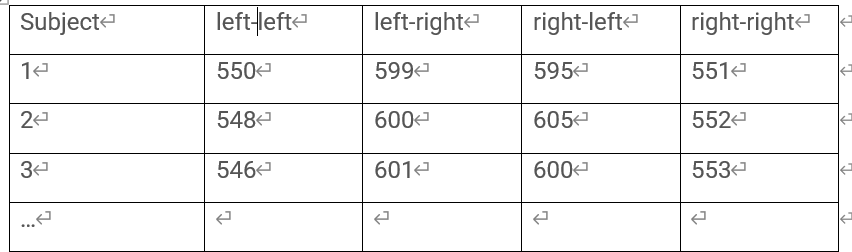
In this case, we each subject have one value on each condition, that is the repeated measure RT were merged. So, How is it different from multi-factor ANOVA?
I am very confused by these questions. If someone could enlighten me by providing me with the answer or giving me the way to know this related issue, I would appreciate it! Thanks!
Comments
Hi,
I suggest reading back in some statistics textbook or on the web, there are many many sources that talk about these issues. In a nutshell, the main difference between these two types of ANOVAs is the error structure of the measurements and their dependences (with repeated measures tend to be more powerful)
Between-subject ANOVAs assume all measurements (for each condition) to be independent. Within-subject ANOVAs, or repeated-measures ANOVA, take into account that the same subject is measured in two conditions. Therefore these two measurements are not independent and uncorrelated anymore. Instead, the measurements for a subject will on average be more similar to each other than to measurements of different subjects. Taking this error structure into account, reduces the overall error that cannot be explained by the model, and therefore tends to be more powerful than between-subject ANOVAs. (Of course there are some drawbacks with repeated-measures ANOVA as well).
Factorial designs (I guess you mean that when you say multi-factor ANOVA), are themselves compatible with repeated- measures and with non-repeated measures. YOu just need to fully cross all levels of one factor with all levels of the other factor.
This was just a very crude explanation. Again, I recommend you read on that in some textbook. You'll probably find plenty better explanations like mine.
Eduard
@eduard Thank you for your suggestion!