

Programming a psycholinguistic experiment on OpenSesame

Hello, I have to program a psycholinguistic experiment for my master's thesis, and I'm having a very hard time programming it in OpenSesame. Can anyone help me?
A short description of my experiment: In my experiment, participants see an object on the screen, hear two voices (a male and a female voice) and are asked to select the most appropriate voice (voice 1 or voice 2) for each object by pressing a button on the computer (1 or 2).
The line drawing of an object appears on the screen for a few milliseconds and then disappears. After about 500 ms, the object reappears together with a recording of a male or female voice saying a short sentence. The object disappears again, then reappears and repeats the sentence with a voice of the opposite sex. It then remains on the screen until the participant presses a the key 1 on the keyboard to indicate that he or she prefers the first voice or the key 2 if he or she prefers the second voice heard. After a pause of about 1,500 ms, the next line drawing appears.
The procedure could be summarized as follows:
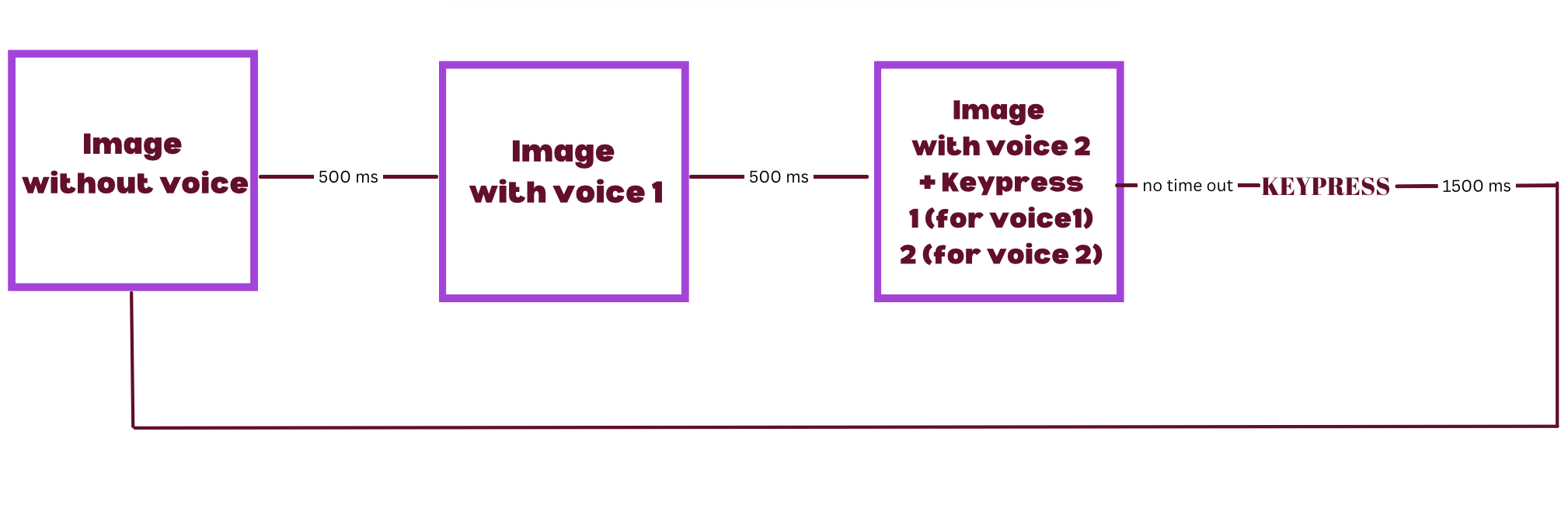
In total, participants see 24 images of objects and hear a male and female voice for each image. The content of the sentences they hear varies from image to image. The order in which they hear the male and female voices is randomized, as is the order in which they see the images.
I've tried this with just one image, but the experiment doesn't work. I think I may have made some basic mistakes. I would be very grateful if someone could give me some sort of step-by-step explanation. Thank you!
Comments
Hi @EmelyBF,
From what I see, there might be some issues in your loop table that could be causing problems, depending on how you've set the variables in the other items. However, it's hard to say for sure without knowing what error you’re encountering when running the experiment.
Could you share your experiment file? That way, I can take a closer look and suggest the best way to fix it—it might be more helpful than step-by-step instructions.
The order in which they hear the male and female voices is randomized
Does that mean each image appears only once, with either a male or female voice first? Or does each image appear twice—once with the male voice first and once with the female voice first?
Let me know, and I'll be happy to help!
Claire
Check out SigmundAI.eu for our OpenSesame AI assistant! 🤖
Hi @cvanbuck,
Thank you for your quick reply! I've attached what I have at the moment, but it's very incomplete. I wanted to try it with just one image and see if it worked, and then add the other 23 images and their audios, but it doesn't work.
Regarding your second question, each image appears three times. The first time it appears alone (without any voice), the second time it appears with one voice (it could be the male or female voice) and the third time it appears with the other voice, and it remains on the screen until the participant presses 1 (to choose the first voice) or 2 (to choose the second voice). Once the choice has been made, a white screen appears for 1500 ms and then it starts with the second image. The order of the 24 images should be randomized for each participant. This means that they won't see the images in the same order.
Thank you for your help,
Emely
Hi @EmelyBF,
Here is a modified version of your experiment, which should now work as expected.
Just add your files to the file pool and update the names in the loop table accordingly.
You might also find this tutorial helpful: Beginner tutorial: gaze cuing // OpenSesame documentation. It covers some useful basics that could help with similar setups (or if you want to tweak things like background color, or whatever).
Hope it helps!
Claire
Check out SigmundAI.eu for our OpenSesame AI assistant! 🤖
Hi @cvanbuck,
Thank you so much for your help! It is a great step forward that the experiment is working and I can actually see and hear something. However, the image only appears twice: once with no voice and a second time with a random voice (male or female), which is very nice! But one step is missing: it should appear a third time with the other voice and then stay on the screen until the participant chooses voice 1 or 2.
It also doesn't react to pressing 1 or 2. It just stays there and I have to stop the experiment. Does this work on your computer? Maybe I'm doing something wrong.
I really appreciate your help :)
Emely
I've tried a few changes and the only way I could get the experiment to go through the three steps while running (image without voice, image with voice 1 and image with voice 2) was to set the image duration and audio duration to "keypress". This way, the experiment moves forward, but the audios are not played until a key is pressed, and at the end, the image stays there and doesn't react to me pressing 1 or 2 to select a voice. Instead, when I press 1 or 2 or any other key, the sound is played again :(
Hi @EmelyBF,
I'm not sure why it’s not working on your computer—it runs fine on mine without any of the issues you mentioned.
Are you using the latest version of OpenSesame? (If not, you can download it here: Download // OpenSesame documentation). Also, are you on Windows, Mac, or Linux?
Claire
Check out SigmundAI.eu for our OpenSesame AI assistant! 🤖
Hi @cvanbuck,
I'm on a Mac. I downloaded the last version of OpenSesame and run the experiment file again, but I still have the same problems. I've attached a link to a video of my screen. In the video, you can't hear the audio, but I do hear the audio the second time the image appears.
https://www.canva.com/design/DAGgHUHk9U8/TlR7iZPfVjoAfToHKVK9rw/view?utm_content=DAGgHUHk9U8&utm_campaign=designshare&utm_medium=link2&utm_source=uniquelinks&utlId=h110e2f2746
Thanks!
Emely
@EmelyBF, that's weird. Have you tried running it with a different backend (legacy or xpyriment)? Do you get any error from the console?
Check out SigmundAI.eu for our OpenSesame AI assistant! 🤖
Hi @cvanbuck,
it tried it out with Experiment and PyGame and it did work! OMG! I can't believe it works! I could even run my first version! I'm going to add the rest of the files to your version and update the names in the loop table.
Thank you so much!!!
Emely
Hi!
I'm still working on my experiment. I have a question about the variables that are collected. I don't want to collect all the variables because I don't need all of them. I just want to know for each image the keyword response, the response time and the order in which the participant heard the voices. So I added the following to the logger: obj_name, img_file, voice1, voice2, keyword_response and response_time. But it doesn't work properly. The data table I get still has a lot of information and not the information I need. In fact, I can only find the keyword_response of the practice trials and not of the experimental trials.
@cvanbuck, could you please help me with that?
Emely
Hi @EmelyBF,
Could you please provide your new experiment file? I have a feeling about what's happening but want to be sure.
Thanks!
Claire
Check out SigmundAI.eu for our OpenSesame AI assistant! 🤖
Hi @cvanbuck,
Here you have a link to the experiment file I was working on when I posted the question. After that, it occurred to me to split the experiment file into two files, one just for the practice session and one for the actual experiment. This way I could actually log the variables I wanted. You also find these files in the link. Maybe you know a better solution, but if not it's ok, I could also do it this way.
https://drive.google.com/drive/folders/1hQtl1T-Edt94ch7cim_t7wS1Cw8CzhUh?usp=share_link
Another problem I have that I really need to solve is that sometimes when I press the key to select voice 1 or 2, the keyword or experiment doesn't respond automatically and I have to press it again. This affects the recording of the actual response time. Do you know why this happens? Maybe the fact that some of the audios are longer than others and even when you don't hear anything, the audio continues for a few milliseconds? When does the reaction time start to be recorded? When the image and sound appear or when the sound ends?
Thank you so much for your help!
Emely
Hi @EmelyBF,
The issue with your variables not logging correctly might be due to having two unlinked loggers (with different variables to log in each) instead of two linked ones (with the same variables). You can download the updated experiment file here.
Regarding the keypress issue, the response time is recorded from the onset of the keyboard object (so at the end of the audiofile). By quickly checking your audiofiles, it's possible that some of them contain extra silence at the end indeed (I found a few), which could introduce slight timing inconsistencies in response time recording. You might want to check your audio files in Audacity (or another editing software) and trim any unnecessary blank sections at the end.
Let me know if these suggestions help!
Claire
Check out SigmundAI.eu for our OpenSesame AI assistant! 🤖