

Counterbalancing 3 sound Samplers online using inline_js or runif statements

Hello all,
I am trying to counterbalance 3 sound conditions for my participants (experiment will be online eventually). A third of the participants should hear a congruent sound with the word stim, a third should hear a tone with the word stim, and a third should not hear anything with the word stim (a silent .wav file).
IDEA 1: I initially thought to write a Run-if statement to specify for which participants to run the Sampler item as follows:
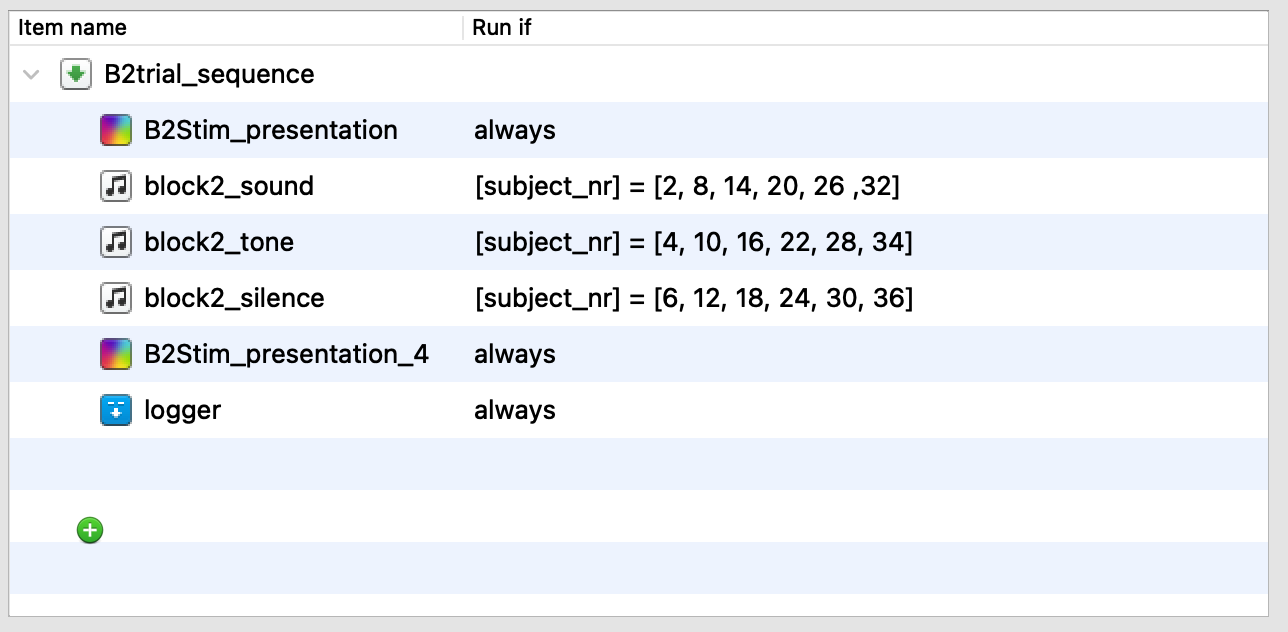
However, this causes the word stim to present without any sound. Is my syntax wrong? It compiles but since I haven't seen any example that does this, then maybe it's not "allowed".
IDEA 2: A second idea I had in order to achieve this was to leave all my Sampler items to Run if "always" and to insert an inline javascript at the beginning of the experiment to control whether these play from there instead.
if(vars.subject_nr in [2,8,14,20,26,32]) {
vars.newCondition1 = "block2_sound"
vars.newCondition2 = "block2_silence"
vars.newCondition3 = "block2_tone"
} else if (vars.subject_nr in [4,10,16,22,28,34]) {
vars.newCondition1 = "block2_tone"
vars.newCondition2 = "block2_sound"
vars.newCondition3 = "block2_silence"
} else {
vars.newCondition1 = "block2_silence"
vars.newCondition2 = "block2_tone"
vars.newCondition3 = "block2_sound"
}
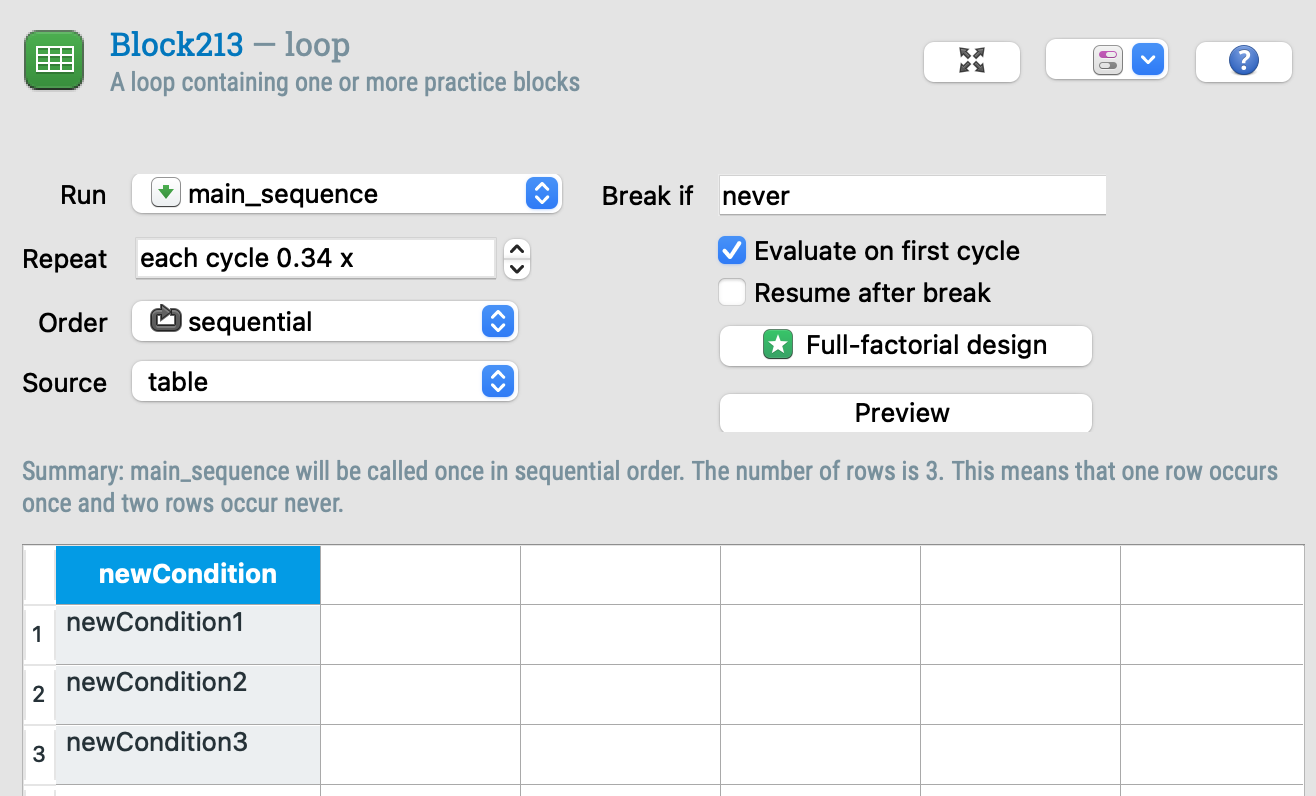
In my Block Loop I added a newCondition, and set Repeat to 0.34 so that only one condition would play each loop.
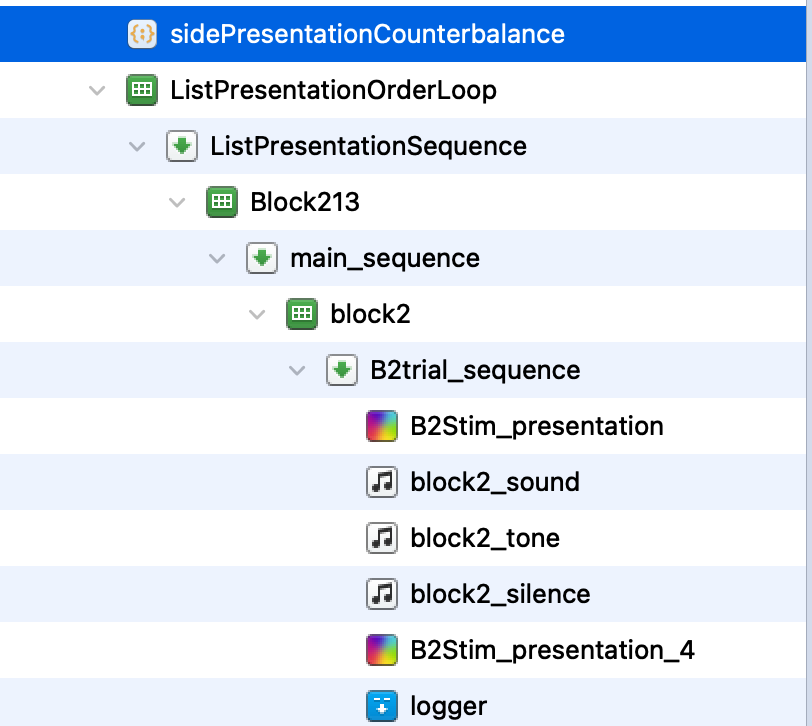
Here is my general flow:
I'm using Psycho for the backend. Audio files are .wav, buffer size 32768 (was making a lot of grainy sounds so I increased it a lot), sampling size 44100.
Any ideas? Thank you!
Comments
Hi @mbcerul4,
Not sure why your experiment does not produce the sound (hard to tell without seeing the code), but here are a few pointers and a couple of solutions I attach to this message (I'm a newbie with Open Sesame and OSWeb, so there may be more elegant solutions, but these do work).
First, though you don't explicitly say so, I'm assuming that your design a between-subjects design (i.e., subjects either hear silence, or tones, or words).
Your IDEA1 is on the right track. but rather than listing all possible subject number values in under the "Run if" condition, you can use something much simpler: the mod operator (if you're not familair with it, check out https://blog.mattclemente.com/2019/07/12/modulus-operator-modulo-operation.html). The mod operator presents the major advantage that it works whatever the subject number is (so you don't have to enumerate all possible values). Be aware also that to run your experiment online with OSWeb, you have to specify the possible subject numbers and so there too it'd be impractical to list all possible values (better to stick to 1,2,3; so that the server loops across these three values only).
IDEA 2 won't work because by limiting the cycle to 0.34, you just won't have any control about what trials are used.
I'm attaching two solutions. Both work in Open Sesame and online as OSWeb experiment on a JATOS server. Both assume that your design is a between-subjects design (though they could be adapted to a within-subject design where you'd like to counter-balance the order of the three sound conditions). Solution 1 is a little longer in terms of structure but it allows you to specific different visual words in the sound conditions. If you actually want to present the same visual words in all sound conditions, then Solution 2 is simpler.
I tried both online. They work. If you plan to eventually use your tasks online, you may want to try out your task as you develop it. I'm currently working on a task that works well in Open Sesame, uses minimum javascript code, but generates errors when run online. Online experiments are still a little touch-and-go (they won'tr execute Python code, and can be picky about javascript code too). If you'd like to try out your task online but don't have your own JATOS server, you can do so for free here: https://www.jatos.org/JATOS-Tryout-Server.html (this is only suitable to try out your task, not to run the actual study, as they delete all files every 24 hours).
To try out your task as a JATOS , make sure to set the possible subject numbers in OSWeb to 1, 2, 3:
Hope this helps!
@Fab Thank you so much for your response! You gave me a lot of ideas for how I could improve the experiment. A little update on what I've done, (and it works!) for the moment is the following:
Then I have my 3 blocks, which have the 3 sound conditions playing, and in the runif I have, only run if [soundCondition1] = sound, etc. In my experiment, each participant goes through all 3 sound conditions. I.e. 20 words are presented with sound, 20 with silence, and 20 with tone.
Block 1
Sound [soundCondition1] = sound
Silence [soundCondition1] = silence
Tone [soundCondition1] = tone
Block 2
Sound [soundCondition2] = sound
Silence [soundCondition2] = silence
Tone [soundCondition2] = tone
Block 3
Sound [soundCondition3] = sound
Silence [soundCondition3] = silence
Tone [soundCondition3] = tone
Maybe the way I did it was a bit convoluted, but for the moment it runs well without any problems.
I leave my solution here in case it is useful to someone else.