

Interpretation of Bayesian 3-way Repeated Measures ANOVA?

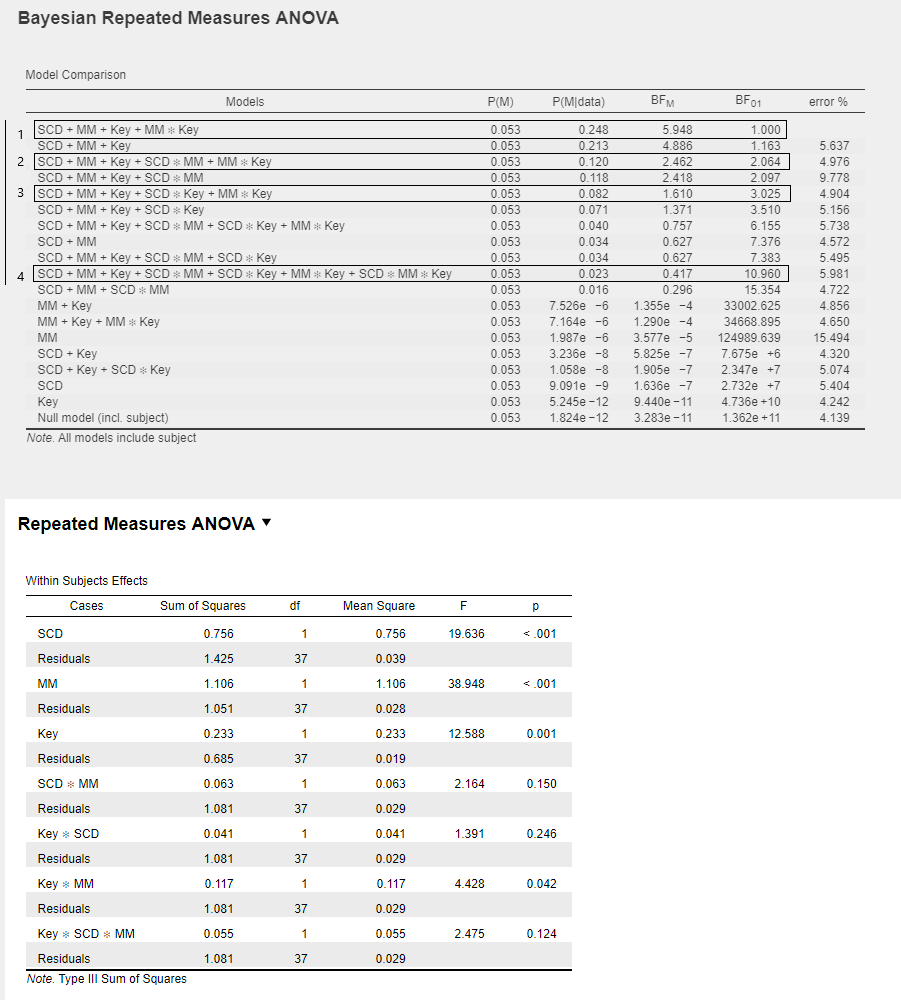
Hello all! I'm looking for help understanding the output for this 3-way RM ANOVA (output attached, along with the traditional ANOVA as well). I have been asked to provide BF01 values for "all nonsignificant effects (using p < 0.05) and interactions", and so that is what I'm trying to do. I have three such interactions; SCD x MM, SCD x Key, and SCD x Key x MM. I've put a box around the first model (which includes only the significant effects) and the three lines that I believe indicate the models I'm looking for.
This analysis was run using the "compare to best model" option in JASP. My understanding is that the BF01 for a given model can be roughly interpreted as the odds that the best model is a better fit than the given model. For instance, the model in Box 2 has a BF01 value of 2.064, meaning the best model is about twice as likely as the model in Box 2. Is that a generally correct interpretation? And, is that interpretation still appropriate for looking at a three-way interaction?
Mostly, I'm just nervous. This is the first time I've used these analyses in a paper headed towards potential publication and I don't feel solid on my understanding of the way to run and/or interpret more complex higher-level interactions. The sources I've found universally stop their discussion of interpretation at 2-way ANOVAs (so, if anyone knows of a source that discusses 3-way ANOVAs, I'd be eternally grateful!).
Please let me know if I can provide more information to help get answers to these questions. Thank you for reading and replying!
Comments
Dear jmbostwick,
This is correct only when you assume the models to be equally likely a priori. The BF generally indicates relative predictive success, so the degree to which the data are more likely to occur under one model than the other. For a blog post on the topic see https://www.bayesianspectacles.org/the-single-most-prevalent-misinterpretation-of-bayes-rule/
2. Otherwise, I think your interpretation is correct.
Cheers,
E.J.