

[DEMO] How to parse a csv to populate a loop (OSWeb 1.4)

Hi there,
If like me you've been trying to work out a way to populate loops with information from a csv file in OSWeb, despair no longer, there are good news: In OSWeb 1.4, this is now possible using two different methods. I briefly describe the first, but really this post is about the second.
The first method, the simplest, is to specify a file as a source for the loop. This was not possible under OSWeb 1.3 or earlier, but it is from OSWeb 1.4. This method is dead simple and will be sufficient in most cases. A great way to load up stimuli lists that you might have built externally in order to fulfill demanding pseudo-randomization rules, or to select a file at random among many - see my post here for a working example: https://forum.cogsci.nl/discussion/7376/try-osweb-1-4-with-new-features-for-online-experiments).
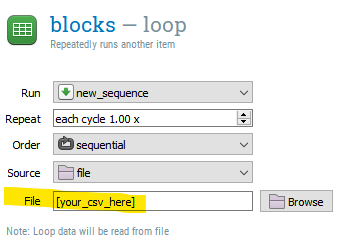
The second method consists in reading a csv file using the csvParse library (now included in OSWeb 1.4), pass the content of that file to an array, and then use that array to populate the trial's information as a sequence runs. Sounds more complicated than method 1? Yes, it is, but this can be useful in certain cases. For example: if you want to populate several loops from the content of a single csv file, or to be able to manipulate the order or the content of certain trials dynamically. I describe how to implement this second method below.
As it name indicates, csvParse is a library allowing users to parse the content of a csv file. The method implemented in OSWeb 1.4 is the Sync API. "The sync API expose a function which expect as input a full dataset as text and which returns the full result set as an array or an object" (https://csv.js.org/parse/api/sync/).
Reading a csv file in OS is easy and done with this code in an inline_javascript object:
var variables = csvParse(
pool['mystim.csv'].data,
{columns: true} // To infer the columns names from the first line
)
Other example declare variables using const, but here I'm using var because I want to be able to reassign the array (I'll use it to shuffle its rows).
Next, we'll declare two functions that we'll use to shuffle the rows of an array, and to retrieve and extract columns based on a property key, respectively.
To shuffle the trials read from the csv file (now stored in the variables array), we'll use this code:
/ --- function to shuffle the rows in a matrix
// We'll use this to shuffle the rows read from the csv file
function shuffleMatrix(matrix){
for(let i = matrix.length-1; i > 0; i--){
const j = Math.floor(Math.random() * i)
const temp = matrix[i]
matrix[i] = matrix[j]
matrix[j] = temp
}
return matrix;
}
// ---
To extract all the elements from an array's specific column based on a property key, we'll use this:
// --- function to extract elements from an array using a property key
function property_value(array, property_key) {
var arr = [],
index = -1,
arrlen = array.length,array_items
while (++index < arrlen) {
array_items = array[index]
if (array_items.hasOwnProperty(property_key))
{
arr[arr.length] = array_items[property_key]
}
}
return arr;
}
If we want to shuffle the trials, we can do so like so:
var variables=shuffleMatrix(variables)
If the csv file contains trials in a very specific, pre-established order and we do not want to disturb that order, then we should not include the code line above.
(take a breath at this stage if you need it; the scariest bit of code is over!)
At the moment, we have an array (variables) that contains the information from the csv file, with headers obtained from the csv's first line. Next, we're going to extract the different columns and store them in specific arrays. In this example, we're reading from mystim.csv, which contains 17 lines. The first contains the headers (picture, correct_response, textstim), and the next 16 lines correspond to 16 trials:
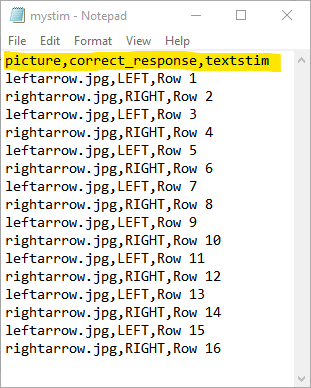
Let's create specific arrays to store the pictures, the correct_responses, and the textstim contents:
vars.pictures = property_value(variables, 'picture') vars.textstims = property_value(variables, 'textstim') vars.correct_responses= property_value(variables, 'correct_response')
At this stage, we have three arrays containing 16 rows each. All that's left to do is to retrieve the appropriate information from these on every trial. To do so, we'll use a variable that counts the trials. We'll then use that variable to extract the content of a specific row in each array. We need to initialize this variable at the very beginning of the experiment:
vars.trialscounter=0
We'll increment this variable by one unit at the end of every trial.
This method means that as our four blocks of four trials run, we'll be able to retrieve the correct trial information from the pictures, textsimsand correct_responses arrays. That is, the trial counter will keep incrementing in every trial, regardless of which block we're in. So, trialscounter will go from 0 to 3 in the first block (since it contains 4 trials) and so we'll be retrieving information from rows 0 to 3 in the pictures, textsimsand correct_responses arrays. Then from 4 to 7 in the second block, etc.
We'll do so by executing this code to at the onset of every trial:
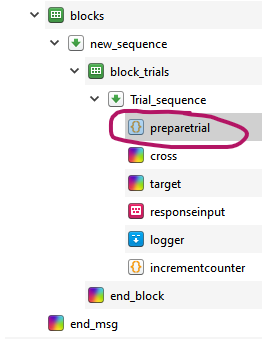
vars.arrow = vars.pictures[vars.trialscounter] vars.msg = vars.textstims[vars.trialscounter] vars.correct_response = vars.correct_responses[vars.trialscounter]
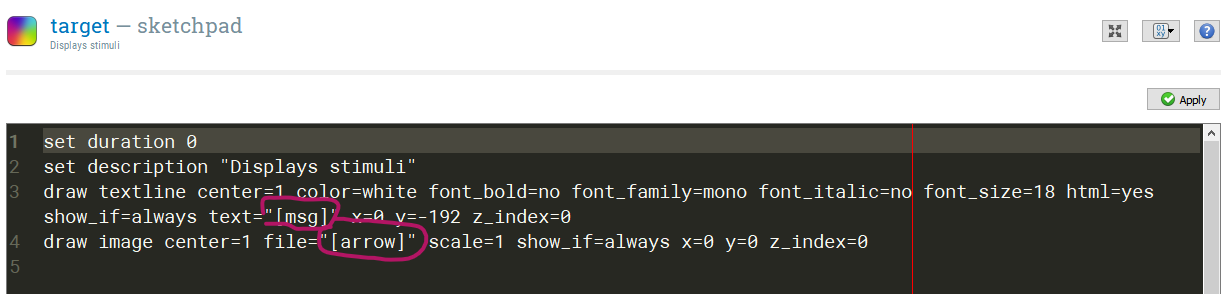
In our example, a sketchpad called "target" is used to display a picture (arrow) and a text message (msg). Note that we're defining the correct response as correct_response. By doing so, we don't need to define the correct response in the keyboard object we're using to take the participant's response (because OS automatically looks for correct_response if no other correct response variable is specified).
Now all we need to do is to make sure to use the labels corresponding to the variables we just defined wherever we want to present stimuli:
Finally, at the end of each trial, we need increment the trials counter (failing to do so would mean that the same first trial would be repeated throughout the task):
vars.trialscounter+=1
A couple of important points more...
(1) Because we're reading the trials' details from a csv file, storing that content in arrays, and using these to populate a loop table, the source for the loop is table and not file. This brings up the issue of how to set the size of this table. We do not need to worry about setting the columns, for these are automatically created when we define the arrow, msg and correct_response variables. The number of rows is an issue, however. Ideally, we would want to define it dynamically. However, as far as I'm aware, there is currently no method to set the number of trials using code in an inline_javascript object. Hence, we must ensure to create a number of rows in the table that fits the task characteristics, In our example, we have 4 blocks of 4 trials each, so we must include 4 rows:
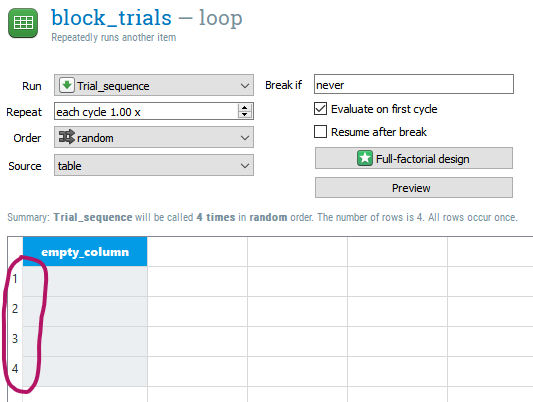
Note that you could also use other combinations (8 blocks of 2 trials, or even one block of 10 trials and another with 6, etc.). The key point is to make sure that the total number of trials in the task corresponds to the number of trials in the csv file. If it is inferior, the task would run fine, but some of the trials from the csv files would not be presented. It if it superior, the task would crash when it tries to retrieve information from an array that does not contain it (e.g., looking for the 17th row of an array containing only 16).
(2) Note that because we're setting the trial's characteristics on the fly as the trial sequence is actually running, the order property of the loop is actually irrelevant. Whether we set it to sequential or to random will make absolutely no difference (zero, zip, zilch, nada!). This is because at the time OS defines the order of the trials (in preparation of the loop running), the table is actually empty. Each row only gets populated as each trial runs.
Et voilà!
Note that the use of the trials counter allows a good degree of flexibility because this counter can be implemented as we wish. We could even use several counter to count different types of trials, retrieve information from different csv files based on specific conditions, etc.
The task used in this example can be downloaded below.
Hope this helpful.
Fabrice.
_____________________________________________________________________________________
If you found my reply helpful and wish to invite me to a coffee, you can do so here 😉: https://www.buymeacoffee.com/psyfab
Comments
Download the example task here:
[UPDATE] Setting up the loop's number of rows dynamically using Javascript
Following my earlier post, and thanks to pointers from Sebastiaan (https://forum.cogsci.nl/discussion/7412/accessing-and-manipulating-loops-in-javascript#latest), I'm describing a variation of the method described above. The difference is that we no longer need to worry about manually creating a specific number of rows in the loop running the trials.
This means that we can simply leave the
block_trialsloop in its default state, for we'll create the desired number of rows dynamically (i.e., as the task runs). Here's the difference between the block_trials loop in the previous post and the new version:To set up the loop as we want it, we'll use some Javascript code that will be executed before the block_trials loop is called into action. For that, we'll need to pay around with the loop's original matrix (which is called using
runner._experiment.experiment.items._items.block_trials.orig_matrix).Here is the code I use to divide the number of trials read from the csv file equally across the number of blocks (which in this case is 4, but which I retrieve dynamically; the latter method can be useful should one want to set the number of blocks dynamically too at a later stage). Then we'll set the length of the matrix, and then we'll populate each row. The latter is necessary for the program to process all the rows (simply setting up the length of the matrix to, say, 4, but setting content for only one row, will not produce 4 trials when the task runs). I use a loop (with i starting at 1, and running while i is smaller than the matrix's length), and set the content of a row to be the same as that in the prevous row.
var trials_per_block = variables["length"] / runner._experiment.experiment.items._items.blocks.orig_matrix["length"] runner._experiment.experiment.items._items.block_trials.orig_matrix["length"] = trials_per_block for (let i = 1; i < trials_per_block; i++) { runner._experiment.experiment.items._items.block_trials.orig_matrix[i]=runner._experiment.experiment.items._items.block_trials.orig_matrix[i-1]; }That's it, the rest of the task remains the same. This version will run exactly as the previous, but we no longer had to create a specific number of rows manually in the loop table. Setting things dynamically can be interesting and save you time if you plan tasks where you might want to vary the number of trials per block. It can be extended to manipulating dynamically the number of blocks.
The updated task demo is available for download here:
Happy programming!
Fabrice.
👍️