

Messy Log files

I finished constructing a self-paced reading task in Open Sesame, which should record the reading speeds of individual words in 24 sentences divided over three texts of eight sentences. There is also a personalized code and after each text, a comprehension question that should be recorded.
However, every time I run the experiment, the log files are incredibly messy. In the attached file you can see that reaction times to individual words are presented in the columns and the row represents each of the 24 sentences. The experiment, however, also tries to record a lot of surplus data, which makes it hard to read. Currently, the data of the first eight sentences can be found horizontally, yet spaced out in a difficult way (see attached image, red box is word 1 & 2 in text 1, etc.). The second text of eight sentences starts in a different column and is spaced out similarly. Already before this relevant section, there are hundreds of columns in the log file with information that I do not need. I thought this was caused by the loggers not being linked, but linking them did not change anything.
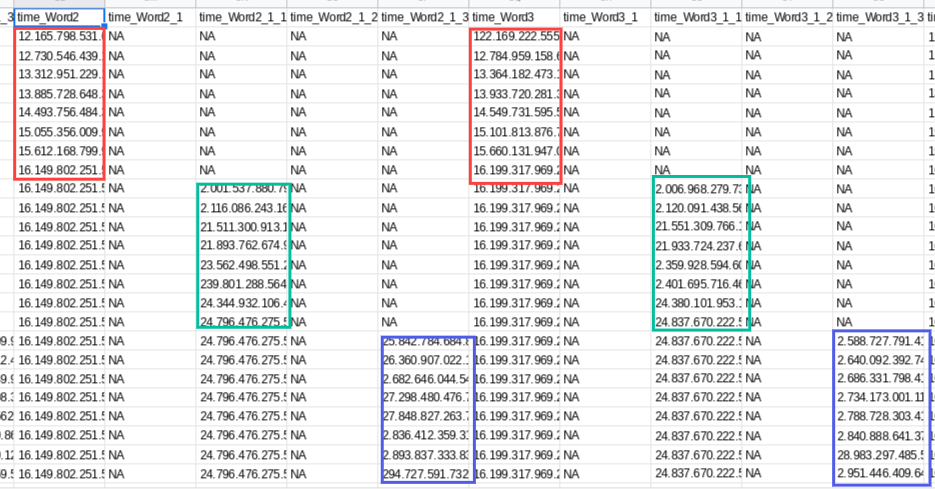
I think this messiness is due to the logging function, which is currently set to 'logging all variables'. When I set it to response-time, it only looks at my data on the sentence level, not the word level (see other attached image), meaning that I only get 24 data points.
I cannot change the sources for these custom variables, would that help?
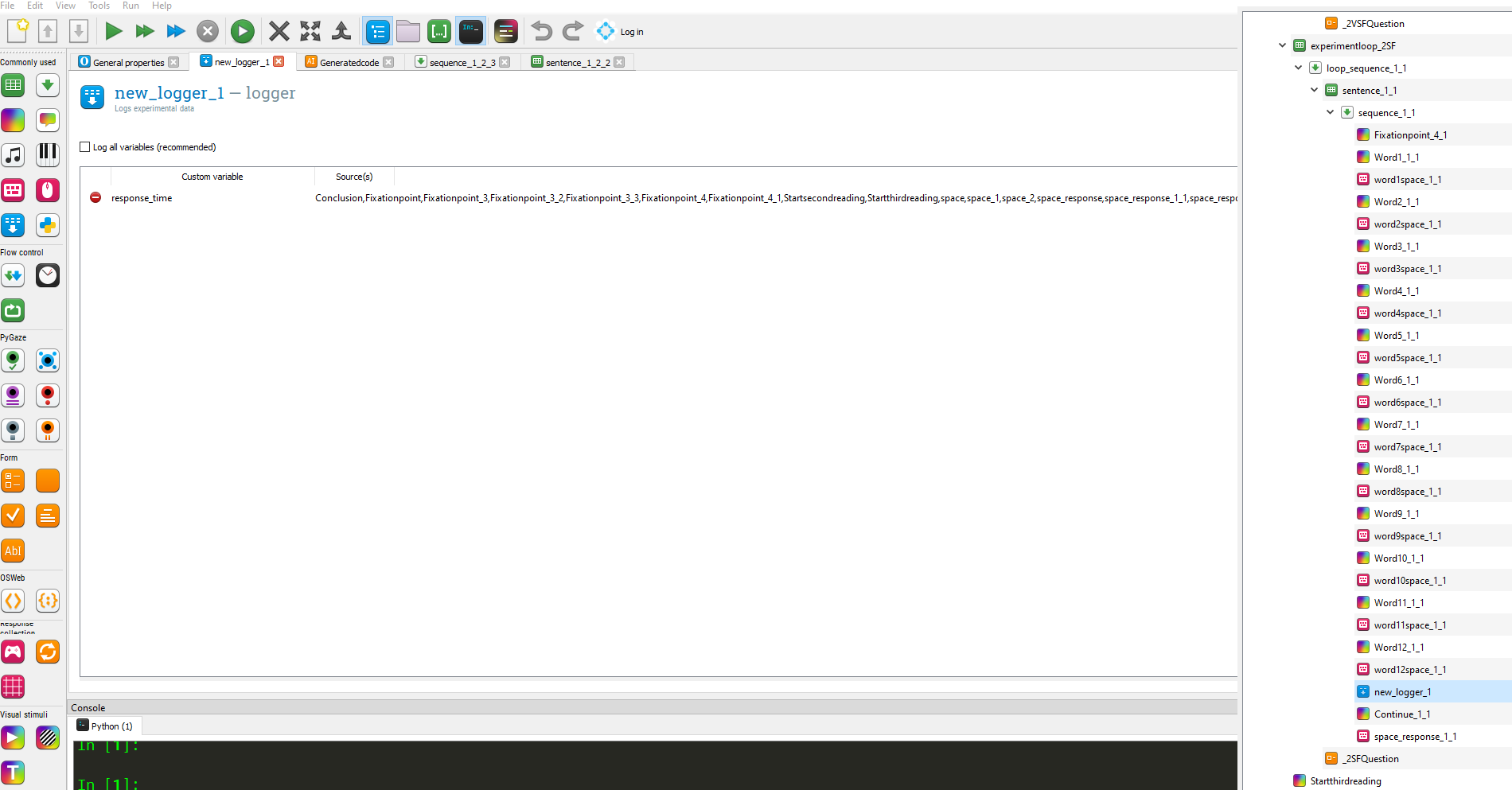
I am, thus, not sure where I should put my loggers and with what variables / functionalities (linked, right?) turned on if I only want to log response time for my words, comprehension questions and a question of a generated code?
The loggers also record time in a cumulative way. I only know the reaction time to one stimulus through subtracting the previous one (some data points in the attached files are in a different magnitude of order, you can ignore this, as this is due to Google Sheets). There is of course a way around this in Excel, but can this be prevented in the program already?
Any help is greatly appreciated.
Nash
Comments
Hi @NashD ,
Looking at your screenshot, you're presenting lots of different words using different
sketchpadandkeyboard_responseitems as part of onesequences . This is possible, but it means that all of these items have their own columns in the log file. That's by design, because in most cases that's what you'd want. In your case, I think you'd probably benefit from having a simplifiedsequencethat presents a word, collects a response, and logs the data, like so:sketchpadkeyboard_responseloggerAnd then you put this
sequenceinside aloopto present multiple words. The result will be a much clearer log file!— Sebasitaan
Check out SigmundAI.eu for our OpenSesame AI assistant!
Thanks @sebastiaan!
This worked and created much better log files. However, I now run into the issue that my experiment has a lot of failed compatibility checks and, thus, no longer works in JATOS. I tried putting the loggers into a dummy loop as it says here, but that gave an error in JATOS stating that it could not run the items of the loop with the looped loggers.
This is what my structure now looks like:
Within the loggers, the structure currently looks like this:
Thanks in advance!
Nash
Hi @NashD,
As @sebastiaan mentioned earlier, the problem comes from the structure of your sequence. is there a reason why you duplicate the sketchpads and keyboard input object instead of using a loop to present Word1, Word2, Word3 etc.? the latter would be a lot cleaner and efficient. Also, it is not recommended (or indeed necessary) to duplicate the logger. In fact, it is recommended you avoid that (this is why you get the error messages in the compatibility check).
If you really must duplicate sketchpads and keyboard input objects (but I'd greatly recommend using a loop instead), you should place the logger at the end of each sequence (e.g., sequence_1_2_2) and list in there the variables from each individual keyboard input object (that is, the response time variable for each keyboard object separately, not just "response_time"). The way you have it implemented at the moment is rather odd and you're ending up with a string containing lots of data that it would make more sense to separate as individual columns in the data output.
Best,
Fab.
Hi Nash,
If you share your experiment, we can demonstrate the change that we have in mind.
Eduard